
AI时代,最重要的就是计算速度。要提升计算速度,除了升级芯片这个“数据处理工厂”外,还有什么途径?
如果将计算芯片看成处理大量数据的“数据处理工厂”,那么内存就是向它传递数据的“数据物流系统”。要提升数据处理速度,不能光看“处理工厂”的机器转得有多快,还要看“物流系统”输入数据的速度有多快。“物流系统”的数据送不进来,“处理工厂”再高效也难以为继。
在AI大模型训练与推理过程中,AI芯片需要在计算单元与内存间反复传递万亿级参数的海量数据。如果内存这一“数据物流系统”无法及时输送数据,计算单元将陷入“机器空转”状态,导致算力闲置浪费。
而高带宽内存(HBM)正是解决传统内存速度瓶颈、满足AI芯片数据需求的关键技术。最新的第六代HBM——HBM4,带宽提升至每秒2TB,相当于一秒钟传输数十部4K电影。有了带宽足够高的HBM,AI芯片才能发挥出它的最强能力。

HBM的产业价值正在凸显。目前,全世界的HBM尤其是最新一代HBM,产能基本集中在韩国的SK海力士、三星和美国的美光这三家内存制造商“大厂”手中。中国也正在HBM国产化的道路上奋起直追。
PART 01
HBM为什么比传统内存速度快得多?
HBM为何能达到传统内存难以企及的速度?
如果把一个传统内存部件比作一层“平房”,那么HBM就是将多层传统内存叠在一起的“楼房”。住进“楼房”的数据能大大减少数据传输的距离,“少跑路”以提高传输速度。在目前的技术规划下,HBM的内存层最多达到16层,远期规划可达24层。
数据从一层内存传递到另一层内存,需要通过“楼房”中的“电梯”——内存层之间的微小通孔。这些微小通孔是借助硅通孔(TSV)技术实现的,TSV能够在每一层内存内部钻出直径仅5—10微米、仅有一根头发十分之一粗细的通孔,这些通孔的内部还要填入铜或钨等导电材料。这些“电梯”可能有数万条,让“楼上楼下”的数据以几乎无延迟的方式直达。
除了内存层之间的垂直“电梯”,在HBM内存架构当中,内存与AI芯片之间还有成千上万条“数据高速路”。这些“数据高速路”是通过一块硅中介层实现的。这块中介层将HBM与AI计算芯片封装在一起,其中设计了超高密度布线,一毫米的宽度内有数以千计的数据通道,使HBM与芯片之间的海量数据畅通无阻。
在以上种种技术的加持下,HBM的速度可以达到传统单层内存的几倍至几十倍,同时单位带宽功耗降至传统方案的一半以下。传统模式下,AI芯片如GPU,周围可能会配置十数颗内存元件,不仅整体排布尺寸无法缩小,还需要更大的电压调节模块;而采用了HBM后,由于一颗HBM可以承担几个到十几个内存部件的功能,GPU周围排布的元件数量就大大减少,不仅数据传输更快,还有体积小、低能耗的优势。
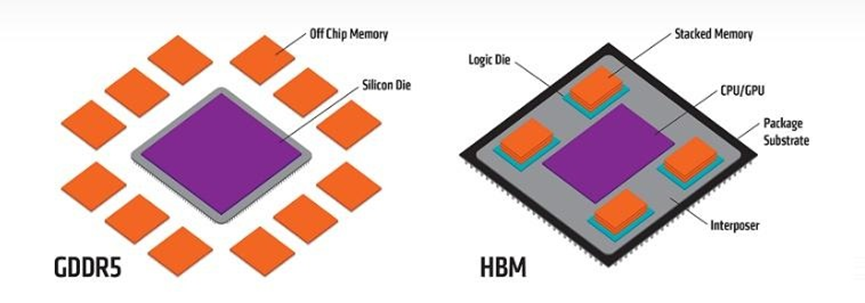
左:传统内存架构形式——多座“平房”
右:HBM架构形式——少量“楼房”
从2016年英伟达Tesla P100显卡中HBM2首次落地以来,HBM始终处于计算技术的最前沿。自2023年起,ChatGPT打开了AI时代的大门,HBM技术也随之进入了更加迅猛的发展阶段。从HBM1算起,当前已发展到第6代,包括HBM2、HBM2E、HBM3、HBM3E和最新的HBM4。
PART 02
HBM市场持续升温,
专用设备是追赶突破关键
受益于AI产业的强劲驱动,全球HBM市场规模持续飙升,并成为少数能和AI芯片供货商议价的领域之一。
2025年11月,SK海力士表示,已与英伟达就2026年第六代HBM的供应完成了价格和数量谈判,价格将比上一代产品高出50%以上。
目前全球内存三巨头正你追我赶地增加产能:三星已决定在2026年底前,将其HBM的月产能大幅提升约50%;SK海力士已将位于韩国清州、被业界视为“HBM4专用工厂”的MX15工厂量产时程提前约四个月;美光公司高管透露,公司已就2026年全年HBM的供应价格和数量与客户达成协议,相关产品已全部售罄……
在中国,截至2025年9月,华为等多家企业已相继披露自研HBM进度。如深圳远见智存科技有限公司表示其HBM第二、三代产品已完成终试,正在推动量产;其第四、五代产品处于研发阶段,已完成前期预研。虽然外媒认为中国HBM技术距全球前沿仍有数年差距,但中国已展现出在HBM赛道上的惊人追赶速度。

HBM内存的制造需要产业链上众多尖端设备协同运作,对设备的精度与可靠性要求极高。例如,构建芯片内部高密度“数据电梯”的关键设备硅通孔(TSV)刻蚀与沉积设备,能制造出密集的垂直电通道,占HBM总成本30%左右,是决定产品性能的核心工序。又如热压键合设备,其作用堪比一位“微雕大师”,通过局部加热和加压,可一次性精准键合多层芯片中成千上万个细如发丝的焊点,为实现12层乃至16层复杂堆叠提供物理基础。据摩根大通预测,2027年用于HBM的热压键合机的整体市场规模将从2024年的4.61亿美元增长至15亿美元。
HBM的生产工艺与传统内存存在显著差异,技术门槛远超传统内存制造设备,这进一步放大了对专用设备的需求。SK海力士副总裁金春焕在接受采访时说:“我们始终坚持长期研发战略,特别是早期在硅通孔技术上的持续投入,以及围绕HBM建立的完整制造与测试基础设施,是我们实现大规模量产并赢得市场的核心竞争力。”
当前,我国HBM产业链在关键设备端的国产化率仍有待提高,这一问题成为制约国产存储突围的短板之一,也成为国产厂商追赶和发力的方向。
HBM作为AI基础设施的“算力咽喉”,其供应能力对下一代AI芯片的落地进度与效能上限至关重要,并深度影响AI芯片厂商、超级计算机及数据中心等应用场景发展。未来,在包括HBM生产设备在内的产业链关键环节,补上国产AI算力基础设施的短板,将能助力中国在全球AI竞争中筑牢核心硬件根基。