
DNA、RNA、蛋白质、单细胞……围绕这些基础生命单元展开的人工智能(AI)模型,正加速走向药物设计等真实场景。业界普遍认为,借助AI参与分子层面的理性设计,有望高效开发出药效更强、毒性更低的内源性药物或生物制剂。但也正因触及生命“底层代码”,相关研发链路格外精密。
以核酸药物研发为例,从原始数据采集到可进入临床验证的候选序列,每一步都需在多重约束下精准权衡:序列如何选择、化学修饰如何搭配、结构是否稳定、是否存在毒性与脱靶风险。任何一个环节出现偏差,都会直接影响药效。过去,即便是成熟的研发团队,也往往需要通过大量湿实验,从成千上万条候选序列中筛选出少数可用方案,周期长、成本高、失败风险大。
正是在这一背景下,在上海市经济和信息化委员会科学智能“百团百项”专项工程支持下,一项由上海科学智能研究院(下称“上智院”)程远团队牵头的围绕多模态RNA设计的模型攻关和应用实践,在上海加速推进。
项目启动一年,团队基于国产算力体系,构建了涵盖10亿级RNA序列、结构、功能与化学修饰信息的多模态基座模型,并在此基础上研发面向RNA设计应用的模型体系。在siRNA与核酸适配体研发中,模型展现出巨大潜力:初步实验验证显示,上智院研发的模型体系辅助siRNA虚拟筛选效率提升1.6倍以上,可降低约90%的体外湿实验成本;核酸适配体筛选效率较传统SELEX方法提升上千倍。阶段性成果已在针对高血脂、高血压等慢性病的siRNA药物设计中完成了初步体外实验验证。


(面向AI和生命科学交叉的重大课题,上智院和复旦大学建立联合攻关团队)
问题倒逼转向,产研协同打造数据基座
在核酸药物研发领域,mRNA疫苗作为核酸药的重要品类之一,在2021年新冠疫情期间展现出巨大潜力。此后,2023年、2024年连续两届诺贝尔生理学或医学奖被授予与该领域高度相关的研究,足见科学界于核酸药物这一新药物模型的认可与期待。
在核酸药物研发领域,siRNA(小干扰RNA)是另一条公认极具潜力的重要技术路线。它不直接作用于蛋白,而是精准靶向并降解特定mRNA,从遗传信息传递的中间层拦截疾病进程,有望攻克许多以往“不可成药”的靶点;同时siRNA可通过递送系统,经细胞内吞作用进入细胞内,这为治愈慢性乙肝及其他疾病提供了可能性。不过,尽管其基因沉默机制早在2006年即获诺贝尔奖认可,高质量实验数据却长期匮乏,研发仍严重依赖经验和试错,难以实现规模化提效。
2024年春,成立半年的上智院生命科学团队在调研微观建模课题过程中了解到合作方大睿生物在siRNA药物设计中的需求:现有方案多依赖专家经验,亟需数据驱动的方法。“但要数据驱动,首先得有数据。”上智院生命科学方向主任研究员郭昕回忆。
双方决定从数据入手。研发团队依托智能体技术,从全球五大专利局的公开渠道抓取相关专利文本,经大语言模型初筛,并结合大睿生物药物研发经验,筛选出包含具体序列与药效信息的高价值专利。工程团队对流程进行系统化改造,效率提升10倍以上,并统一了siRNA化学修饰命名体系,最终形成包含9.6万条化学修饰siRNA序列的数据库。(数据集已开放:https://sais.org.cn/data-publish)
这份数据的价值不仅在于其目前全球最大的规模,更在于服务真实药物研发场景,上智院工程师王先胜说:“如果连数据的表达方式都不贴近研发问题,模型就很难真正发挥作用。”
在这一项目中,上智院提出的“强AI+深领域+重工程”协同模式得到了深刻体现:AI团队负责多模态融合与模型架构,企业提供专利筛选、修饰模式标准化等药物研发专业方案,工程团队搭建数据处理和专家标注系统。
早期专利中,siRNA药物因修饰不全面导致效果不佳,大睿生物总监卜中元带领团队帮助筛选出具有高成药潜力的专利数据用于训练。他表示:“高质量、高成药潜力的数据是AI模型的‘燃料’。我们在药物研发场景有比较深的经验,这有助于项目伊始就瞄准临床需求。”
数据有了,如何处理海量专利是另一挑战。算法团队最初采用人工下载、OCR解析再上传至云平台处理的流程,郭昕坦言这一方式略显“草台班子”:“处理单篇专利尚可,但面对上万篇的规模,这条路显然走不通。”直到工程团队介入,将全流程进行系统改造,构建出高效、可扩展的数据处理链路,算法团队得以专注模型创新,而数据清洗与整理工作也实现了稳定、可靠的交付。
模型迭代:先理解RNA,再设计RNA
数据逐步完善的同时,模型研发并非一蹴而就。早期虚拟筛选效果并不理想,单一任务模型难以支撑复杂设计。团队还意识到:没有对RNA的整体认知,就算有高质量siRNA数据,也难做好siRNA药物设计。
于是,一个看似“绕路”的决定被提上日程——先打造基础模型,把RNA的语言学会。
今年11月,由上智院联合复旦大学打造的女娲RNA基础模型面世。模型整合10亿级RNA序列、结构、功能和化学修饰等多模态数据,覆盖mRNA、ncRNA等主要类型,将多种与RNA设计密切相关的模态首次融合于统一的大模型范式中。“它更像一台RNA生物学模拟器。”郭昕形容,“为下游设计提供稳定、通用的表征能力。”多项国际基准测试显示,该模型在RNA结构预测、逆折叠等任务中取得领先表现。
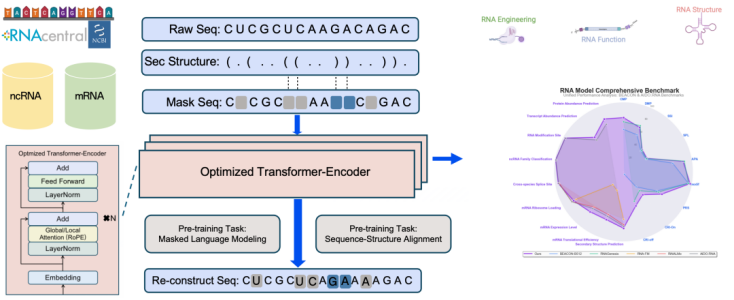
(女娲RNA基础模型技术架构)
在基础模型与高质量数据逐步到位后,面向应用的设计功能探索水到渠成。
RNA基础模型解决的是“如何理解RNA”,而药物研发需要的是“如何设计RNA”。围绕明确场景,团队构建了两条应用路径:一是siRNA方向,覆盖序列生成、虚拟筛选、毒性与稳定性评估;二是核酸适配体方向,从靶向分子骨架出发生成候选序列,经物理特性筛选进入实验验证。下游模型结构轻量,仅需几层多层感知机(MLP)或简单的循环神经网络(RNN),即可完成具体任务。
siRNA因其长效特性,在慢性病治疗中可显著提升患者依从性;核酸适配体则能用于生物传感与药物递送,为靶向治疗开辟新路径。“上智院的模型研发,一直秉持着‘研’以致用的理念,从场景出发确定模型所需的数据和功能。”郭昕说。
加速分子筛选:星河启智与Lab-in-the-loop
女娲RNA基础模型以及研发的配套多模态RNA设计模型,为核酸药物筛选提供了具有巨大潜力的理性设计解决方案。然而早期药物候选分子筛选是一项系统化工程——当面对缺乏数据的新靶点,或需同时满足药效、靶向性、安全性等多重目标时,纯计算模型仍显得力不从心。
项目的一大转折发生在星河启智科学智能开放平台(https://aistudio.ai4s.com.cn)上线之后。该平台定位智能体原生的全链路科学智能开放平台,由上海市整体布局、上智院和复旦大学牵头研发,于2025年7月面世。它秉持“以科学家为中心”的设计理念,将数据、模型、算力、实验设备等科研要素整合集成,为复杂科研任务提供了基础支撑。
项目组将此前困扰数月的一项高难度靶点研究迁移至该平台。首先利用“科学宇宙”模块,对该靶点相关的海量文献进行了深度挖掘。不同于传统的关键词搜索,平台的智能体帮助团队快速梳理出该基因在相关疾病中的表达特点,并提供了以往药物设计中的经验性结论。
紧接着,多个AI模型开始协同计算,在沉默效率、脱靶风险等多目标约束下,于数小时内从上万条序列中筛选出约200条高分候选。这些序列被送入体外湿实验进行评估验证,返回的结果用于对这个靶点的模型的专门优化。经过3–4轮小幅迭代,所筛选出来的序列已经具备极高的成药潜力。
这正是“Lab-in-the-loop”流程的体现——数据、实验与AI模型之间形成了闭环迭代。依托星河启智平台,上智院联合大睿生物、镁伽科技正共同推进该范式落地,其中自动化实验部分由镁伽鲲鹏实验室4.0承接,可实现湿实验机器人7*24小时不间断运行,采集记录全场景全流程实验数据。
借助这一流程,目前已有超过5个靶点的siRNA设计流程完成验证,模型辅助筛选效率比传统方式提升约1.6倍,核酸适配体筛选效率较SELEX方法提升上千倍。明年起,更多科研人员可借助星河启智平台,调用这些工具开展研究。
“‘问题共定义、路径共探索’不是一句空话。”卜中元感叹道:“从明确数据标准到共建‘干湿闭环’,这种深度融合让研发效率发生了质变。AI不仅提供了新工具,更带来了一种可扩展的新范式。”

(大睿生物实验室)

(镁伽科技自动化实验室)
应用落地:精准医疗的上海路径
在上海市“百团百项”专项的支持下,上智院的RNA模型体系已实现阶段性落地。目前,300亿参数的基础模型已完成训练,覆盖模态最全、支持任务最广,并基于全国产算力平台构建,正在慢性病代谢调节、神经退行性疾病等方向上持续探索。
“在早期的多项体内实验观测中,siRNA的有效剂量可以在半年内都维持稳定水平,这意味着一次给药可持续约半年。”卜中元表示,这对慢性病患者意味着用药频率和负担的大幅降低。
研究团队也正将技术拓展至阿尔茨海默病、帕金森病等神经退行性疾病的相关靶点。尽管该领域仍面临靶点有效性验证与药物递送等科学挑战——尤其是RNA药物需穿越血脑屏障的问题,但合作方大睿生物在神经递送方面已有专门方案,为模型设计成果的落地提供了可能。
“从理解RNA到设计RNA,我们做的不是一蹴而就的颠覆,而是一步步可落地的扎实工作”,上智院科研副院长、复旦大学人工智能创新与产业研究院副院长程远总结道,“这也正是科学智能在上海发展的一个缩影——在系统布局下持续推进,在场景驱动中务实创新。”